Data Analytics Stages
Data Maturity in Organizations
Clustrex collaborates with organization across a variety of domain to move them up to the highest levels of maturity in their data journey where DATA is the key business differentiator.
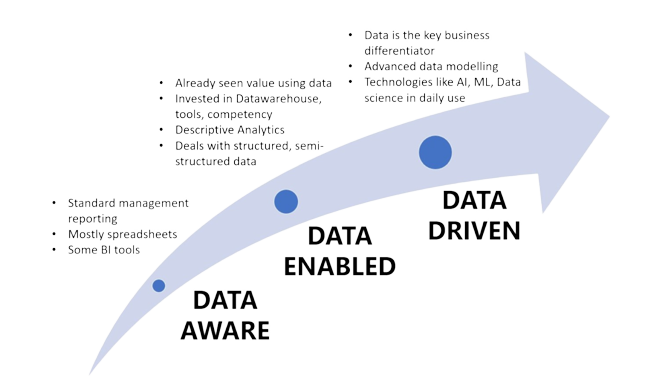
Our Services
Extracting insights from data and enabling, Data-driven Decisions, Healthcare, Energy, Education, and Transportation.
Onboarding the data from various sources like API, XML, JSON, Databases, Spreadsheets, CSV, Webpages, and more.
Technology: AWS Lambda, Glue, EMR, Nifi, Python, Apache Spark, HDFS, ETL Talend
Cleaning, Parsing, Structuring, Deduplication, Enrichment, Validation.
Technology: Python, Pandas, Numpy
Build large scale data warehouses that support analytics tools, dashboard by storing data efficiently, delivering results to many concurrent users.
Technology: PostgreSQL, AWS RDS
Helps in having common data definitions, avoiding data silos and inconsistencies, improving data quality, enforcing policies to prevent misuse and errors, ensuring regulatory compliance.
Technology: Data Dictionary, Policy Management and Access control, Audit logs
In the Big Data world, data visualization tools are key to analyze large scale information and implement data-driven decisions. Visualization uncovers trends, patterns and outlier in data.
Technology: Tableau, AWS QuickSight, D3.js
Extraction of meaningful information from semi structured data, and images is key to many industries and domains. Use our data extraction as a service to pull information and drive workflows or deliver insights.
Deduplication is a process of identifying and eliminating redundant data from a dataset. Redundant data is becoming a critical issue for organizations across domains such as healthcare, finance, retail, education, and almost anywhere else.
Case Study

1. Education Analytics Application
Objective:
Develop a comprehensive analytics platform to empower mentors with actionable insights on student performance, attendance, and learning progress.Scope:
Deliver intuitive visualization charts, comprehensive performance reports, and an integrated data analysis ecosystem to enhance educational outcomes.Key Features:
Technologies Used:
Frontend:
D3.js – for dynamic and interactive data visualization charts.Backend:
Python – for data processing and application logic.Cloud Infrastructure:
Value Delivered:
Challenges Faced:
2. Point of Interest (PoI) Identification Using AI & Geospatial Data
Objective:
Automate the identification and validation of Point of Interest (PoI) locations by integrating geospatial data, AI-powered image recognition, and automated data enrichment processes.Scope:
Deliver an end-to-end solution capable of analyzing large datasets, retrieving updated business and location information, and leveraging AI to accurately identify PoIs using satellite imagery.Key Features:
Technologies Used:
Programming Language:
Python – for data processing, integration logic, and AI interfacing.Database:
PostgreSQL – for storing and managing large volumes of structured and geospatial data.APIs and Services:
Cloud Infrastructure:
AWS – for scalable compute, storage, and deployment of the application components.Value Delivered:
Challenges Faced:

3. Optimizing Revenue Cycle Management (RCM) in Healthcare
Objective:
Streamline and optimize the Revenue Cycle Management process to enhance financial efficiency, reduce claim denials, and improve operational transparency for healthcare organizations.Scope:
Develop an integrated RCM solution that automates claims processing, ensures compliance, and provides actionable insights into financial operations.Key Features:
Technologies Used:
Healthcare Platforms:
Athenahealth, Nextech – for seamless data integration with EMR and PMS systems.Programming & Data Processing:
Python – for custom logic, data pipelines, and automation scripts.Data Warehousing & ETL:
Databases:
PostgreSQL – for structured data management.Visualization & Reporting:
Tableau, AWS QuickSight – for interactive dashboards and business intelligence reporting.Value Delivered:
Challenges Faced:
No. 51/2 - II Floor, Pandian Complex, Madipakkam Main Road, Madipakkam, Chennai-600091
A3, Anbu Complex, Balaiah Garden, (near Ponniamman Koil) Madipakkam,
Chennai-600091
Clustrex Inc
5121, Collin McKinney Pkwy, Ste 500, #1099, McKinney,
TX 75070
Reach out to us and connect with our team to explore new possibilities.

